
When SMS messages fail, the root cause is usually one of five categories: sender registration issues, consent and compliance gaps, content filtering triggers, poor list hygiene, or technical routing/configuration errors. The fastest path to recovery is a structured diagnostic sequence that isolates failure patterns by carrier, template, and audience segment.
Why This Matters
Deliverability issues can silently crush pipeline performance. Teams often keep sending while guessing at causes. A systematic troubleshooting workflow reduces downtime and prevents repeated suspension or filtering events.
See how much revenue SMS could add to your HubSpot stack
Five inputs. Industry-backed benchmarks. Get your projected annual SMS revenue in under 30 seconds.
Calculate My SMS ROI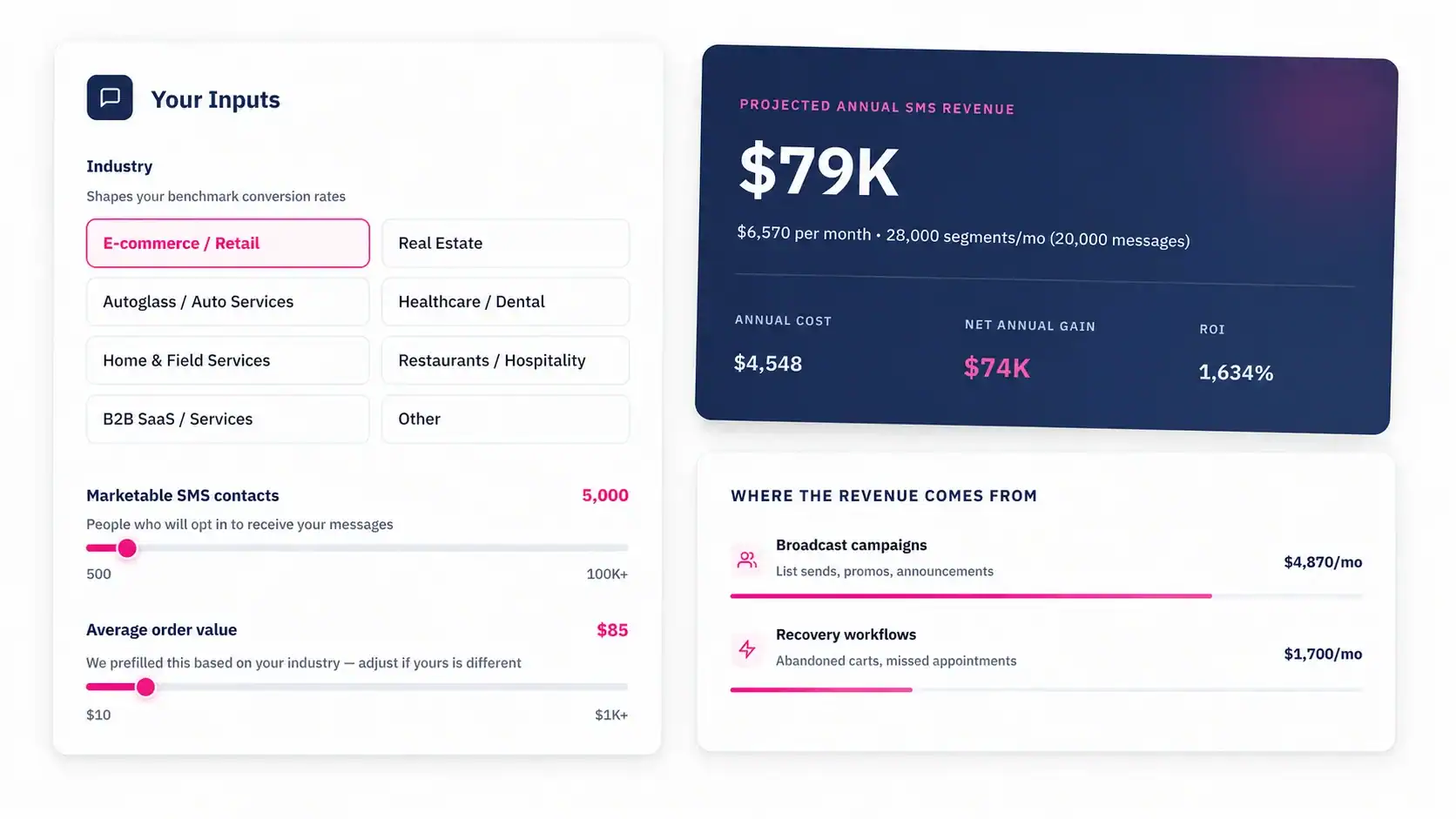
Top reasons SMS messages fail
Failures often map to policy and quality signals, not just platform outages. If sender identity is weak, consent evidence is unclear, or templates look promotional without proper context, carriers may filter or block traffic. Poor list quality and repeated sends to disengaged contacts also increase risk.
Treat deliverability as a quality system spanning compliance, copy, data, and technical operations.
Diagnostic framework: 5-step triage
Start by segmenting failures by carrier, template, use case, and contact cohort. Then validate sender registration status and recent compliance changes. Next, audit copy patterns and link behavior. After that, review list hygiene and suppression controls. Finally, test technical routing and event logging.
This sequence helps teams avoid random fixes and identifies root causes faster.
High-impact fixes by failure type
If issues are compliance-led, tighten consent verification and opt-out controls. If content-led, rewrite risky templates and reduce spam-like patterns. If data-led, remove low-quality cohorts and stale contacts. If technical-led, fix routing, retries, and provider configuration with test cohorts before full relaunch.
Always relaunch gradually and monitor by carrier to confirm recovery.
Turn HubSpot Into A Real-Time SMS Engine with Message IQ
- 98% SMS read within 3 min
- 78% Buy from first responder
- 21× More likely to qualify
*MessageIQ is an Integrate IQ product built natively for HubSpot by the same team.
Prevention system for stable deliverability
Run weekly quality checks on template performance, unsubscribe trends, and delivery codes. Maintain a change log for template edits and workflow updates. Establish pause criteria for risk signals so issues are contained early.
Programs with proactive monitoring usually recover faster and avoid repeated disruption.
| Failure Signal | Likely Root Cause | Immediate Action | Long-Term Fix |
| Sharp drop in delivered rate | Registration/compliance mismatch | Pause impacted campaigns and verify sender setup | Quarterly sender + compliance audit |
| Carrier-specific failures | Template or routing issue by carrier | Run controlled tests per carrier and template | Carrier-aware template governance |
| High unsubscribe spike | Expectation mismatch or over-messaging | Reduce send frequency and review consent text | Lifecycle-based frequency caps |
| No inbound replies logged | Webhook/routing configuration error | Validate event mappings and owner routing | Automated monitoring for reply sync health |
| Suspension warning | Policy violation risk pattern | Escalate to compliance + revise campaigns | Approval workflow with pre-send risk checks |
Step-by-Step Implementation
- Pause high-risk sends and preserve logs for analysis.
- Classify failures by carrier, template, workflow, and segment.
- Validate sender and registration status against active use cases.
- Audit consent proof and suppression logic for impacted cohorts.
- Rewrite high-risk templates and reduce aggressive send patterns.
- Relaunch with controlled cohorts and monitor daily for one week.
- Document root cause and add preventive control to QA checklist.
Practical Checklist
- Direct-answer section present at top of article for answer-engine extraction.
- Question-style headings used for major reader intents.
- Examples and operational details included to improve citation-worthiness.
- At least one comparison/reference table included for skimmability.
- FAQ answers written in concise 1-3 line format for AI retrieval.
- Content includes trust note and practical limitations where relevant.
Frequently Asked Questions
Why do messages fail even when the platform says sent?
Sent status may only indicate platform handoff, not final carrier delivery. You need delivery-state and carrier-level diagnostics.
Is deliverability mainly a technical problem?
Not usually. Compliance, consent quality, and template content often drive failure patterns.
How quickly can we recover from filtering?
Recovery time depends on root cause and corrective action quality. Controlled relaunches typically perform better than immediate full-volume retries.
Should we keep sending while troubleshooting?
For affected segments/templates, pause is usually safer until root causes are addressed.
What metric should trigger investigation?
Sudden delivered-rate drops, rising unsubscribe rates, and carrier-specific anomalies should trigger immediate review.
Can poor list hygiene cause carrier issues?
Yes. Low-engagement or improperly consented lists increase complaint and filtering risk.
Do template edits really affect deliverability?
Yes. Wording, link patterns, and message intent clarity can materially change filtering outcomes.
How often should we run deliverability audits?
Weekly for active programs, with deeper monthly diagnostics and post-incident reviews.

Get 300+ SMS Templates
Enter your details to download the PDF instantly.
Download Started!
Your 300+ SMS Templates PDF is downloading now. If it didn’t start, click here.
Conclusion
Deliverability is operational reliability plus compliance discipline. Teams that diagnose systematically and enforce preventive controls turn SMS from a fragile channel into a dependable revenue workflow.

